Settings
Before you begin reading this article, please take your time and read part 1, Structuring a .NET Core application – Part 1: Separation of Concern and part 2, Structuring a .NET Core application – Part 2: Inversion of Control first.
The previous two parts demonstrated how to split your application into smaller parts, each with their own small task, e.g. Separation of Concern. You’ve also seen how to use dependency injection in different types of applications in a standardized way with as little code reuse as possible. With each library handling all the registration of its services and dependencies.
In this part, we will move a bit back from our libraries and into the application side. In this part, we’re going to look into settings and how to use them.
You can find the source code for this article here: https://github.com/nickfrederiksen/net-core-structure/tree/part-3-settings
We have 3 libraries, used by four different applications. Each of our three libraries has services that requires some form of configuration.
The DAL library needs a connection string. The Azure Storage library needs some keys to access an Azure Storage account. And the email library needs some information about the SMTP server, the sender, CC, BCC and so on. To configure that, is quite easy. Just put all the configurations into a config file, load it up and we’re good to go. But is that really the best way to do that?
We have 4 different applications, each of these has different ways to handle configuration:
- ASP.NET Core uses appsettings.json and environment variables.
- Azure Functions uses environment variables
- The console app uses command line arguments.
- The UWP app doesn’t seem to have anything buildin, but we will have our settings stored in a settings.ini file, just for fun.
In .NET Core, you can mix and match all you want, and we can get appsettings.json functionality in all of our application types. However, each application type has its own usages.
The ASP.NET Core application is usually run on a web server of sorts, where config files can help setup multiple instances of the same application with the same settings.
The Azure Functions is running in a “serverless”, (read: hosted), Azure environment, where you might want to have your configurations managed by Azure, since we don’t really know, or care about, where the code is running. So, here we’ll use environment variables instead of a config file.
A CLI application could use a config file, but since it’s a console line interface application, I might want to have the settings be set as arguments instead of a file. This way we can easily batch different jobs, with different configurations and execute from the same folder.
And our UWP is a piece of end-user software. We cannot expect the end user to know how to modify a json/xml/text config file, set/change environment variables or load up some proprietary database file just to change the sender email address. In this case, we might want to build a “settings”-page within the application.
If we had to add logic, within all our libraries to handle each of these scenarios. Our code would be massively cluttered and full of duplicate code. So instead, we need to let our application do the configuration of our libraries instead.
But first, we need to modify our libraries so that they can be configured:
Please note, much of what I describe in this part is described in detail here: https://docs.microsoft.com/en-us/aspnet/core/fundamentals/configuration/options?view=aspnetcore-3.1
Configuring the services
To get started, we need to add a single nuget package to our libraries:
- Microsoft.Extensions.Options.ConfigurationExtensions
This package will add an extension method to the IServiceCollection that looks like this: “Configure<TOptions>(Action<TOptions> configureOptions)”
You might know this method from ASP.NET Core, as it comes as part of that.
What it does is quite simple: First, it creates an instance of TOptions, then it calls the configureOptions action delegate to populate the options instance. Then it adds it to our DI using 3 different interfaces:
- IOptions<TOptions>
- IOptionsMonitor<TOptions>
- IOptionsSnapshot<TOptions>
I won’t go into detail about these interfaces here but take a look at the link above. It describes it quite well.
So, we will configure our options using the Configure extension method and the we can inject, using DI, those options into our different services as needed.
First, we’ll need to create our options class. I usually create a folder called “Options” where I put my options classes. I will only show one example here but check out the code on github to see all of them.
public class AzureStorageOptions
{
public string ConnectionString { get; set; }
}
This example is for the Azure Storage project. And, as you can see, an options class is not very complex.
We will then register that option, using the Configure method from above:
services.Configure<AzureStorageOptions>((options) => options.ConnectionString = "connection string");
See, simple. But wait. We have still not configured anything. Just hardcoded the connection string directly into our code. And further, we aren’t using the options anywhere.
That shit won’t fly!
Negan, A-hole extraordinaire – The Walking Dead
So, first of we need to move the configuration out of our library. To do that, I will just add the configureOptions task delegate to the, in this case, AddStorage method. And it will look like this:
public static void AddStorage(this IServiceCollection services, Action<AzureStorageOptions> configureStorage)
{
services.Configure(configureStorage);
... omitted ...
}
And thus, the configuration is no longer our concern. Excellent! Now we need to get rid of this abomination:
services.AddSingleton(provider => CloudStorageAccount.Parse("connection string"));
We need to use the connection string from our options, and not this hardcoded value. And that is actually quite simple:
services.AddSingleton(provider =>
{
var options = provider.GetRequiredService<IOptionsMonitor<AzureStorageOptions>>();
return CloudStorageAccount.Parse(options.CurrentValue.ConnectionString);
});
This code gets the options from the. And since we cannot run the application without it, it is fair to use “GetRequiredService”. We then use the current value of the options instance to get our connection string and pass it into the Parse method. Simple.
But there’s more. We have a QueueService, that has a hardcoded value as well. We have to move that out into our configuration logic as well.
So first up, we need to extend the options class:
public class AzureStorageOptions
{
public string ConnectionString { get; set; }
public string QueueName { get; set; }
}
And currently, the QueueService looks like this:
public class QueueService : QueueClient<QueueModel>, IQueueService, IQueueClient<QueueModel>
{
public QueueService(CloudQueueClient cloudQueueClient)
: base(cloudQueueClient, "queue-name")
{
}
}
We need to remove the hard coded “queue-name” and use the QueueName property from the configured options. And that is quite simple:
public class QueueService : QueueClient<QueueModel>, IQueueService, IQueueClient<QueueModel>
{
public QueueService(CloudQueueClient cloudQueueClient, IOptionsSnapshot<AzureStorageOptions> options)
: base(cloudQueueClient, options.Value.QueueName)
{
}
}
As you can see, we just inject the options as an IOptionsSnapshot instance and use the value from there. And the wonderful part here is, that you can inject the options anywhere in your code. Not just within your library. But also, in the user interface or logging, not that you should log the connection string, but you could log or display the queue name in the UWP app and ignore the value in the ASP.NET application. It’s up to you. All that matters is that our library and its services has been configured.
Configuring the applications
All we need to do now, is to configure the applications themselves. And it’s also quite simple.
ASP.NET Core
Most of the ASP.NET Core configuration can be automated using the Bind() extension method on the IConfiguration interface. The extension method is located in this namespace: Microsoft.Extensions.Configuration.
All you need to do is update your call to the AddStorage method into this:
services.AddStorage(options => this.Configuration.Bind("azureStorage", options));
The Bind method, reads a section in the appsettings.json file called “azureStorage” and maps the values onto the passed in options instance.
Our appsettings.json then looks something like this:
"azureStorage": {
"ConnectionString": "connection string",
"QueueName": "queue-name"
}
As you can see, the json properties maps directly to the properties of our options class.
You might want to move the connection string into the “ConnectionStrings” section. That can also be done, quite easily: Please note: Do not have connection strings that points to your live database in your version control. That’s an easy way to get in the news.
By using the connection string section in the appsettings.json, we can configure our Azure App Services with connection strings more easily.
First, update the appsettings.json:
"ConnectionStrings": {
"azureStorage": "connection string",
},
"azureStorage": {
"QueueName": "queue-name"
}
We also need to update our configuration code:
services.AddStorage(
options =>
{
this.Configuration.Bind("azureStorage", options);
options.ConnectionString = this.Configuration.GetConnectionString("azureStorage");
});
First, we bind the settings from the “azureSettings” section, then we set the connection string from the connection strings section. That’s it really.
Azure Functions
Azure functions are a bit different in the way it handles settings. It uses environment variables instead of configuration files. However, in a local dev environment, it does have a configuration file: local.settings.json. And it might look something like this:
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true"
}
}
Nothing radical. All we have to look at, is the Values section. This is a simple key-value object. Nothing special. So, we add the configurations for the Azure storage example at it looks like this:
{
"IsEncrypted": false,
"Values": {
"AzureWebJobsStorage": "UseDevelopmentStorage=true",
"azureStorage-ConnectionString": "connection string",
"azureStorage-QueueName": "queue-name"
}
}
To use those values in our application, all we need to do, is to read the environment variables:
services.AddStorage(
options =>
{
options.ConnectionString = Environment.GetEnvironmentVariable("azureStorage-ConnectionString");
options.QueueName = Environment.GetEnvironmentVariable("azureStorage-QueueName");
});
There you have it. And note that we don’t have to create an instance of the “AzureStorageOptions” class. It has already been instantiated.
You can read more about it here: https://docs.microsoft.com/en-us/azure/azure-functions/functions-run-local?tabs=windows%2Ccsharp%2Cbash
Console applications
In our console application, in this example at least, we don’t want any configuration files. We want all our configurations to come from the argument list.
First up, we need to parse the argument list. This code is not pretty, but bear with me:
private static IReadOnlyDictionary<string,string> ParseArgs(string[] args)
{
var values = new Dictionary<string, string>();
for (int i = 0; i < args.Length - 1; i++)
{
var key = args[i];
var value = args[i + 1];
if (key.StartsWith('-'))
{
key = key.Substring(1);
values.Add(key, value);
}
}
return values;
}
We then need to pass those values into the configuration code:
static async Task Main(string[] args)
{
var configurations = ParseArgs(args);
var builder = Host.CreateDefaultBuilder(args);
builder.ConfigureServices((hostContext, services) =>
{
services.AddStorage(
options =>
{
options.ConnectionString = configurations["azureStorageConnectionString"];
options.ConnectionString = configurations["azureStorageQueueName"];
});
});
await builder.RunConsoleAsync();
}
Then, we can call the application like this:
IoCTest.Applications.CLI.exe -azureStorageConnectionString “connectionstring” -azureStorageQueueName “queuename”.
Universal Windows Application
As the previous examples show, we can store and retrieve our application configurations differently. But our services stay the same. The same goes for UWP applications.
But, instead of relying on environment variables, setting up appsettings.json or adding command line arguments. I will demonstrate how to read configurations from an ini file and use the values in our services.
First up: The config.ini file.
Create a file called config.ini. It is important, that this file is always being copied to the output directory:
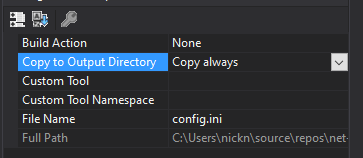
Otherwise the application cannot find the file.
Next up, add our values:
azureStorage-ConnectionString=connection string
azureStorage-QueueName=queue-name
Then, in the App.Services.cs file, we will load and parse the file: (I know, this logic should be put elsewhere, “Separation of concern” and all that. But for this example, I’m keeping it simple.)
private IReadOnlyDictionary<string, string> LoadSettings()
{
var lines = File.ReadAllLines("./config.ini");
var values = lines.Select(l => l.Split("=")).ToDictionary(k => k[0], v => v[1]);
return values;
}
And then, set the values:
private void ConfigureServices(IServiceCollection services)
{
var settings = this.LoadSettings();
services.AddStorage(
options =>
{
options.ConnectionString = settings["azureStorage-ConnectionString"];
options.QueueName = settings["azureStorage-QueueName"];
});
}
And that’s it. Four applications, four different types of managing configurations, 3 services all configured the same way.
TL;DR
Application settings, as the name implies, are application specific. You may have services shared across different application types. But the way each application handles configurations may differ from one another.
So, instead of letting the libraries do all the configurations and letting the guess what kind of application we’re running. We will let the application do the configuration for us, and then pass those down into our services in a standardized way.
Read more
If you haven’t already, please take a look at the other posts in this series:
Structuring a .NET Core application – Part 1: Separation of Concern
Structuring a .NET Core application – Part 2: Inversion of Control